LLMs can sound confident even when they are wrong. That makes evaluation one of the most important parts of building any AI product.
The tricky part is that “correct” does not always mean the same thing. For a math problem, correctness may mean the exact final answer. For a chatbot, it may mean the answer is helpful and grounded. For a retrieval system, it may mean the model used the right context and did not hallucinate.
In this article, we will look at how to evaluate LLM outputs in a practical way, what metrics actually matter, and how to build an evaluation workflow that works in production.
Why LLM evaluation is harder than it looks
Traditional software is deterministic. If you pass the same input to a function, you usually expect the same output. LLMs are different. They generate language probabilistically, which means the same prompt can produce slightly different answers across runs.
That creates several challenges:
- The answer can be technically different but still correct.
- The answer can look fluent while being factually wrong.
- The answer can be partially correct, which makes binary scoring too simplistic.
- Some tasks have no single perfect answer at all.
This is why LLM evaluation is not just about checking whether the output “looks good.” It is about defining what good means for your use case.
What does “correct” really mean?
Before measuring anything, you need to define correctness for your task.
For example:
- In multiple choice QA, correctness may mean the model selected the right option.
- In information extraction, correctness may mean the model found the right entities and values.
- In RAG systems, correctness may mean the answer is grounded in retrieved documents.
- In creative writing, correctness may mean the response matches tone, style, and intent.
- In customer support, correctness may mean the answer is accurate, complete, and safe.
This is the main mistake many teams make: they use one metric for every task. But LLM evaluation is task-specific.

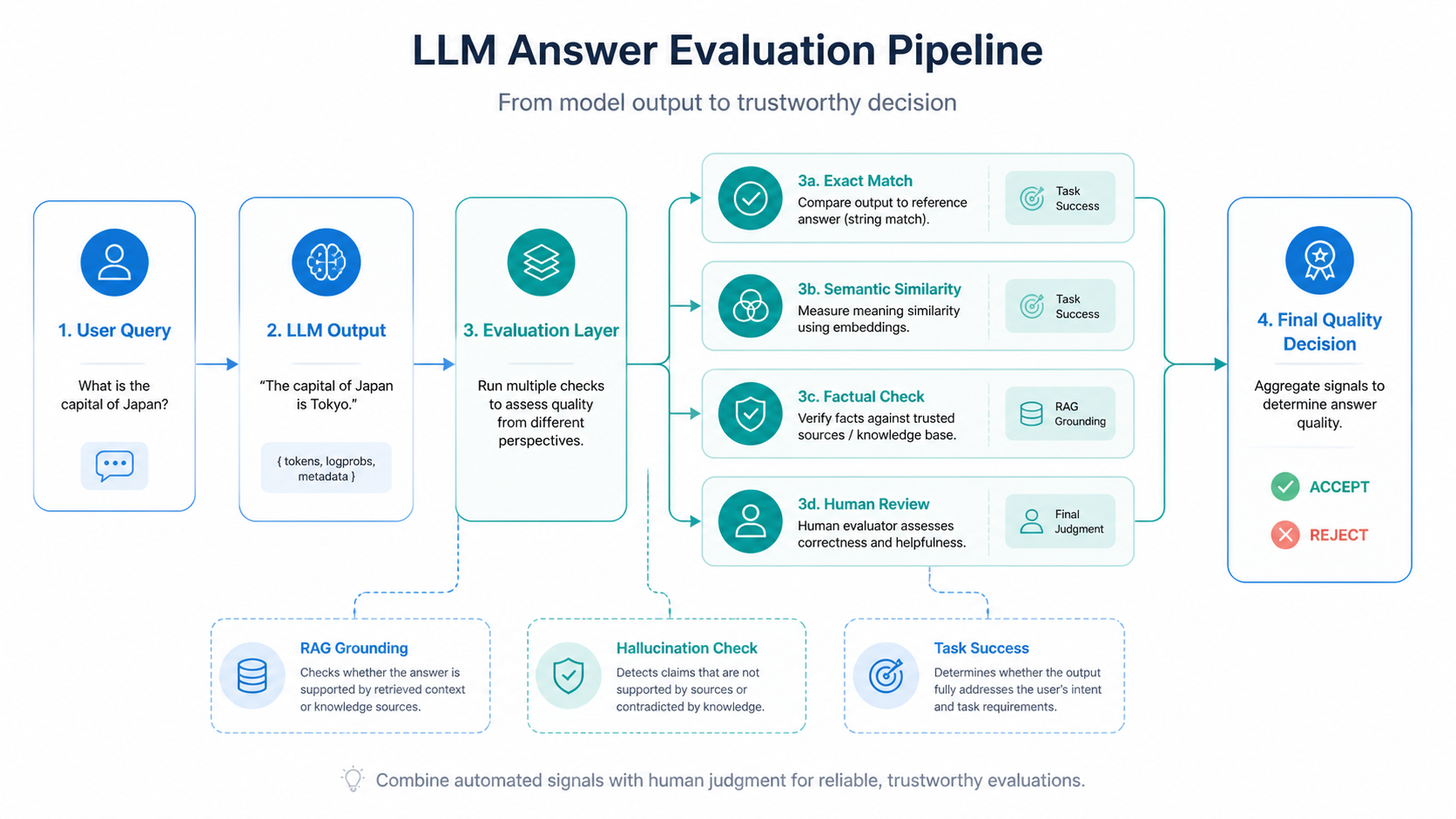
The evaluation stack
A good evaluation system usually has multiple layers.
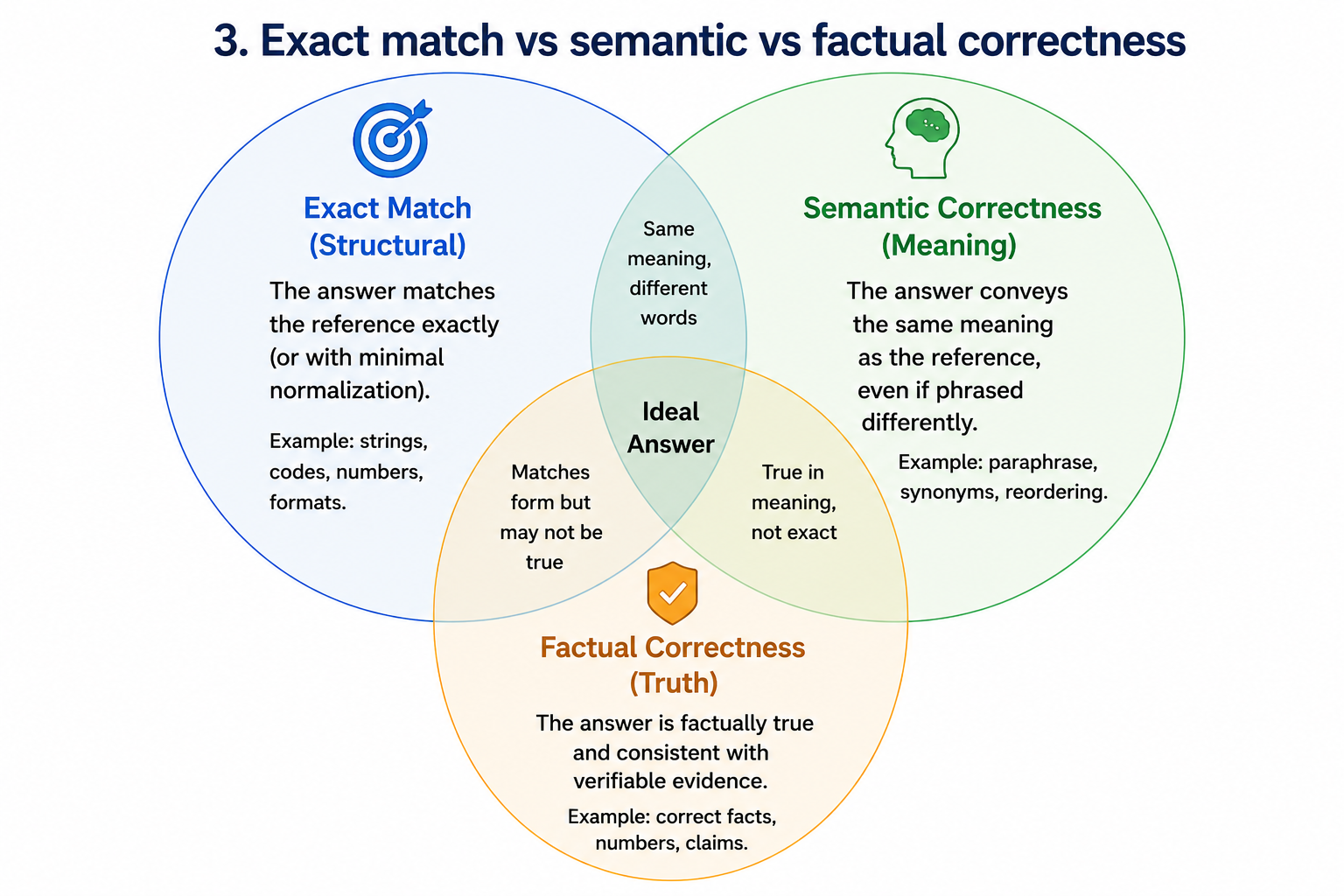
1. Exact match
This is the simplest form of evaluation. If the model must output a specific string, you compare the prediction to the reference answer.
This works well for:
- Math answers with fixed results
- Structured extraction
- Classification labels
- API field values
Example:
If the correct answer is Paris, then Paris is correct and Lyon is wrong.
The limitation is obvious: exact match is too strict when multiple answers can be valid. If the model says “The capital of France is Paris,” exact match may still fail if you expected only Paris.
2. Semantic similarity
Sometimes the meaning is correct even if the wording is different. In those cases, semantic similarity is more useful than string matching.
This compares the meaning of the generated answer with the reference answer, usually using embeddings or another similarity method.
It helps when:
- The answer can be phrased in multiple ways
- The model returns a full sentence instead of a short label
- You care about meaning, not exact wording
But semantic similarity is not enough on its own. Two answers can be semantically similar while one is still wrong in a factual detail.
3. Factual correctness
This matters when the LLM is expected to answer based on real-world facts or retrieved documents.
A response may sound fluent, but if it invents a date, name, number, or policy, it is not correct.
You can evaluate factual correctness by checking:
- Is the answer supported by the source context?
- Does it contradict known facts?
- Are the claims verifiable?
- Are any important details missing or hallucinated?
This is especially important in RAG systems, healthcare, finance, and legal applications.
4. Task success
Sometimes the real goal is not just a correct sentence, but a correct outcome.
For example:
- Did the support bot solve the issue?
- Did the summarizer preserve the important information?
- Did the extraction pipeline fill the right database fields?
- Did the agent finish the workflow without breaking anything?
This is a more practical evaluation style because it measures whether the model helped the system achieve its actual purpose.
Main evaluation methods
There is no single best method. In practice, teams combine several.
Human evaluation
Humans judge whether the response is correct, useful, safe, and aligned with expectations.
This is the gold standard when:
- The task is subjective
- The output is open-ended
- You are building your initial test set
- You need to validate automated metrics
The downside is cost and inconsistency. Humans are slower, and two reviewers may disagree.
To reduce inconsistency, define a rubric. For example:
- 1 = incorrect
- 2 = partially correct
- 3 = mostly correct
- 4 = correct and complete
LLM-as-a-judge
Here, one model evaluates another model’s output.
This is useful because it is faster and cheaper than full manual review. It works especially well for:
- Helpfulness
- Relevance
- Style
- Completeness
But it should be used carefully. A judging model can be biased, overly lenient, or inconsistent. It should not be the only source of truth.
Automated scoring
This includes methods like:
- Exact match
- Precision and recall
- F1 score
- Similarity thresholds
- Rule-based validation
- Constraint checking
These are ideal for structured tasks where the answer can be objectively verified.
Pairwise comparison
Instead of asking “Is this answer good?”, ask “Which answer is better?”
This is often more reliable than scoring each answer independently. It works well for:
- Prompt/version comparisons
- A/B testing
- Ranking multiple model outputs
Metrics that actually matter
The metric depends on the use case.
For extraction tasks
Use:
- Precision
- Recall
- F1 score
- Exact field match
These tell you how often the model extracted the right values without false positives or false negatives.
For classification tasks
Use:
- Accuracy
- Precision
- Recall
- F1
- Confusion matrix
These help you understand not just whether the model is right, but what kind of mistakes it makes.
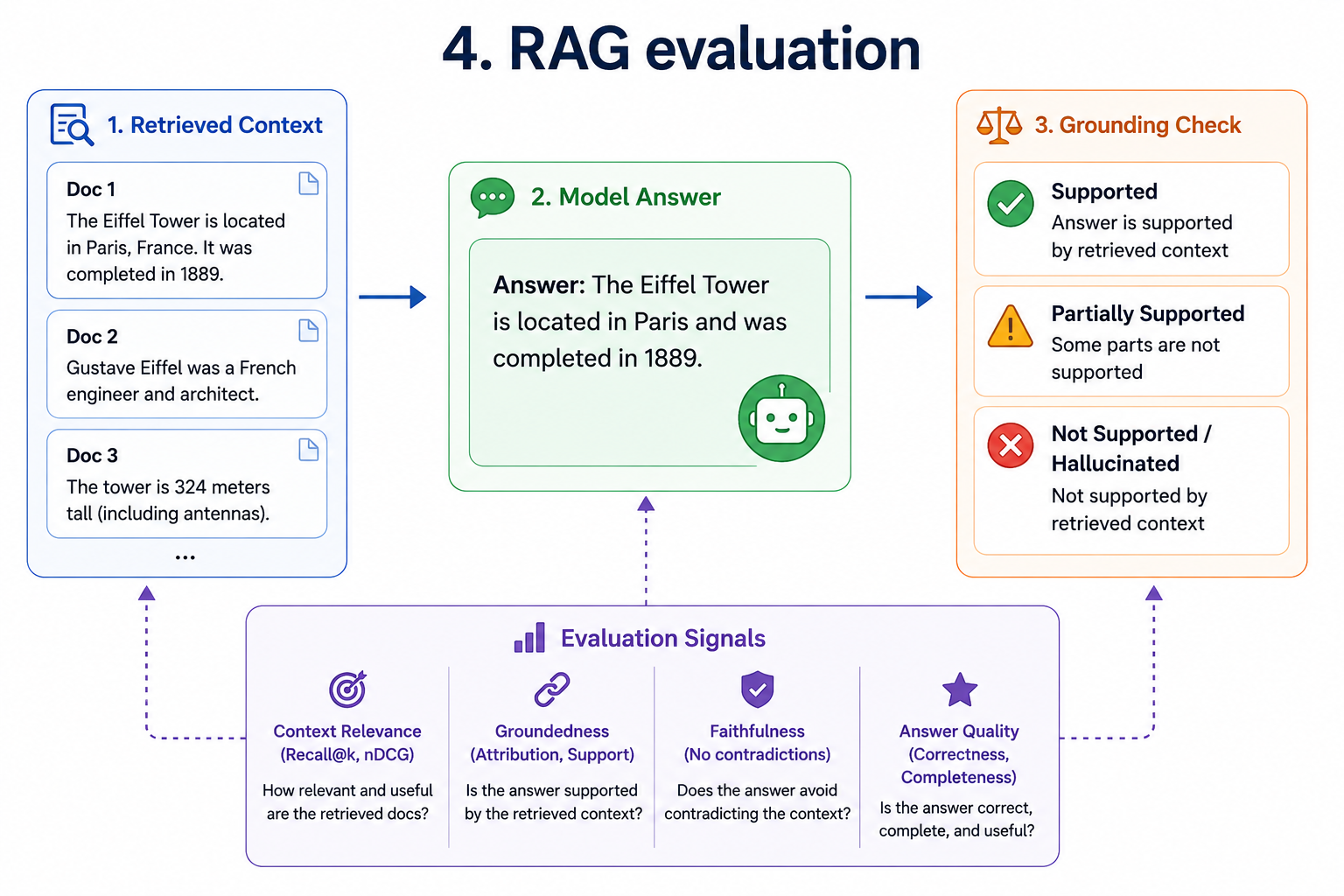
For RAG systems
Use:
- Context relevance
- Answer faithfulness
- Groundedness
- Citation accuracy
A RAG answer can be fluent and still be wrong if it is not grounded in the retrieved context.
For generation tasks
Use:
- Human ratings
- LLM judge scores
- Task completion
- Tone/style alignment
For open-ended generation, one metric is never enough.
A practical evaluation workflow
A good evaluation pipeline usually looks like this:
- Collect a representative test set.
- Define the task and what correctness means.
- Create reference answers or expected behaviors.
- Run the model on every test case.
- Score outputs automatically where possible.
- Review edge cases manually.
- Track results over time.
- Re-run evaluation after every prompt, model, or retrieval change.
This is important because LLM quality can degrade silently. A prompt tweak that improves one case may break ten others.
Common mistakes
Using only one metric
Many teams rely on just accuracy or just BLEU-style similarity. That is rarely enough.
Evaluating only a few examples
A model can look great on five examples and fail on fifty others. You need a broad test set.
Not separating task types
A support bot, a summarizer, and a classifier should not use the same evaluation rules.
Ignoring edge cases
The weird examples are where models often fail. Include ambiguous, adversarial, and low-quality inputs in your test set.
Trusting fluent output too much
A polished answer is not necessarily a correct answer. Fluency can hide hallucination.
How to think about production evaluation
In production, evaluation is not a one-time event. It is a continuous process.
You should measure:
- quality before deployment,
- quality after changes,
- quality on real user traffic,
- quality on failure cases,
- and quality over time.
That means keeping a living benchmark set and tracking regressions whenever you change:
- the prompt,
- the model,
- the retriever,
- the tool logic,
- or the system instructions.
The goal is not just to make the model better once. The goal is to keep it from getting worse.
A simple decision rule
If your task has a single objective answer, use deterministic checks first.
If your task has multiple valid answers, use semantic checks and human review.
If your task depends on context, use groundedness and factual validation.
If your task is subjective, use rubrics and pairwise comparison.
That is the most practical way to think about LLM evaluation.
Final thoughts
Evaluating an LLM is not about asking whether the output sounds right. It is about defining correctness for your task and measuring it in a way that matches reality.
The best teams do not rely on one metric. They combine automatic checks, human review, and production monitoring to catch different kinds of errors.
If you build evaluation well, you do not just measure model quality. You create a feedback loop that makes every version of your AI system more reliable than the last.